[Kubernetes] CPU 스로틀링을 조심해!
![[Kubernetes] CPU 스로틀링을 조심해!](/content/images/size/w960/2025/04/146611020-a2a47b95-c57e-46f9-add4-2efc586e921c.png)

종종 시간이 남으면 레딧에 들어가서 IT 소식들이나 정보들을 둘러보는데
어느날 피드를 보다가 어떤 광고 하나를 보게되었다
개발팀이랑 플랫폼팀 중 누가 쿠버네티스 Request 를 설정할지를 두고 싸우는 모습인데
실제로 비슷한 경험을 하고있어서 너무 공감이 되었다.
쿠버네티스를 다루다보면 빠지지 않는 뜨거운 감자 Request & Limit.
개중에서도 CPU 에 대한 Limit 은 항상 논란의 중심에 있는데
쿠버네티스 커뮤니티를 살펴보면,
"통제를 벗어난 파드가 과다하게 리소스를 점유하는 현상을 방지해야한다"
라는 찬성측과
"남는 리소스가 있음에도 사용하지 못하게 만드는건 그저 낭비이다"
라는 반대입장이 첨예하게 갈린다.
회사에서도 Request 와 Limit 을 몇 으로 설정할지 고민하고 있던 와중에
왜 유독 CPU Limit 만 이렇게 극명한 입장차이가 생기는지 궁금했졌다.
이번 포스트를 통해서 바닥까지 파보자!
Request? Limit?
쿠버네티스에 어플리케이션을 올릴 때 필수로 설정하는 Request 와 Limit.
간단하게 정리해보면 아래와 같다
Request : 파드에 할당할 최소한의 성능 개런티. 적어도 이 값 만큼은 남은 리소스가 클러스터에 있어야 파드가 할당된다
Limit : 파드가 쓸 수 있는 하드 리밋. 파드는 이 이상을 넘어서는 리소스를 사용할 수 없다.
이 값들은 파드가 사용하게 될 CPU 와 메모리 각각에 적용가능한데
간단한 예시를 보면 아래와 같다.
resources:
requests:
memory: "256Mi"
cpu: "0.5"
limits:
memory: "512Mi"
cpu: "1"
위 설정을 가진 파드는
최소 0.5 코어, 256MiB 메모리가 보장되어야 스케줄링되고
최대 1 코어, 512MiB 메모리까지만 사용할 수 있도록 제한된다.
수십 ~ 수백개의 파드가 같은 서버에서 돌아가는 쿠버네티스의 특성 상 위와같은 제한이 없다면
어떤 미친 파드가 혼자서 모든 리소스를 다 점유해버리는 현상이 발생할 수 있음을 충분히 예상할 수 있다.
필요한 만큼 보장해주고 그 이상은 제한한다.
간단하고 명확하다.
논란의 소지도 없어보인다.
그렇다면 "최대치"를 명확히 제한하는 CPU Limit이 왜 이렇게 논란이 되는 걸까?
압축가능한 자원, CPU
테이블이 5개 있는 식당에 손님 5명이 방문했다고 치자.
하지만 안타깝게도 이 식당은 그릇이 3개밖에 없다.
따라서 먼저온 손님 3명은 음식을 받지만 나머지 2명은 앞선 손님이 식사를 끝내기까지 자리에서 기다려야 한다.
이 상황을 리소스 관점에서 다시 보면,
테이블(=메모리)은 한 번 자리가 차면 더 이상 손님(=프로세스)이 들어올 수 없고,
그릇(=CPU)은 한정되어 있지만, 손님들이 돌아가면서 음식을 먹을 수 있다.
즉, CPU는 여러 프로세스가 동시에 필요로 하더라도, 운영체제가 시간을 쪼개서 돌아가며 사용할 수 있게 해준다.
이런 특성 때문에 CPU는 "압축 가능한(compressible)" 리소스라고 부른다.
다시 식당 비유로 돌아가면,
그릇이 3개밖에 없지만 손님 5명이 모두 조금씩 번갈아가며 그릇을 사용해 식사를 할 수 있다.
물론 한 번에 모두가 먹을 수는 없으니, 각 손님이 식사하는 속도는 느려지지만
그래도 모두가 조금씩이라도 식사를 할 수 있는 셈이다.
이처럼 CPU는 여러 파드나 컨테이너가 동시에 필요로 하더라도,
운영체제가 각 프로세스에 CPU 시간을 분배해주기 때문에
리소스가 부족해도 "일시적으로 느려질 뿐" 바로 죽지는 않는다.
반면, 메모리는 다르다.
테이블이 꽉 차면 새로운 손님은 아예 들어올 수 없듯이,
메모리가 부족하면 새로 시작하는 파드나 컨테이너는 실행조차 되지 않거나,
이미 실행 중이던 프로세스가 OOM(Out Of Memory)으로 강제 종료된다.
CPU Limit이 논란이 되는 진짜 이유
쿠버네티스에서 CPU Limit을 설정하면, 리눅스 커널의 cgroups와 CFS(Completely Fair Scheduler)가 컨테이너의 CPU 사용량을 감시한다.
컨테이너가 Limit을 초과해서 CPU를 사용하려고 하면, 커널은 해당 컨테이너의 실행을 일시적으로 "멈췄다가" 다시 재개하는 방식으로 CPU 사용을 강제적으로 제한한다.
CPU Limit 이 없는 어떤 파드가 200ms 의 CPU 처리 시간이 필요한 일을 해야한다고 가정해보자

이상적인 환경이라면 파드는 그림과 같이 200ms 동안 CPU 를 오롯이 점유하게 된다.
그러므로 파드는 200ms 의 시간 뒤 원하는 결과를 얻게 된다
이번에는 동일한 파드에 CPU Limit 0.4 를 설정했다고 가정해보자
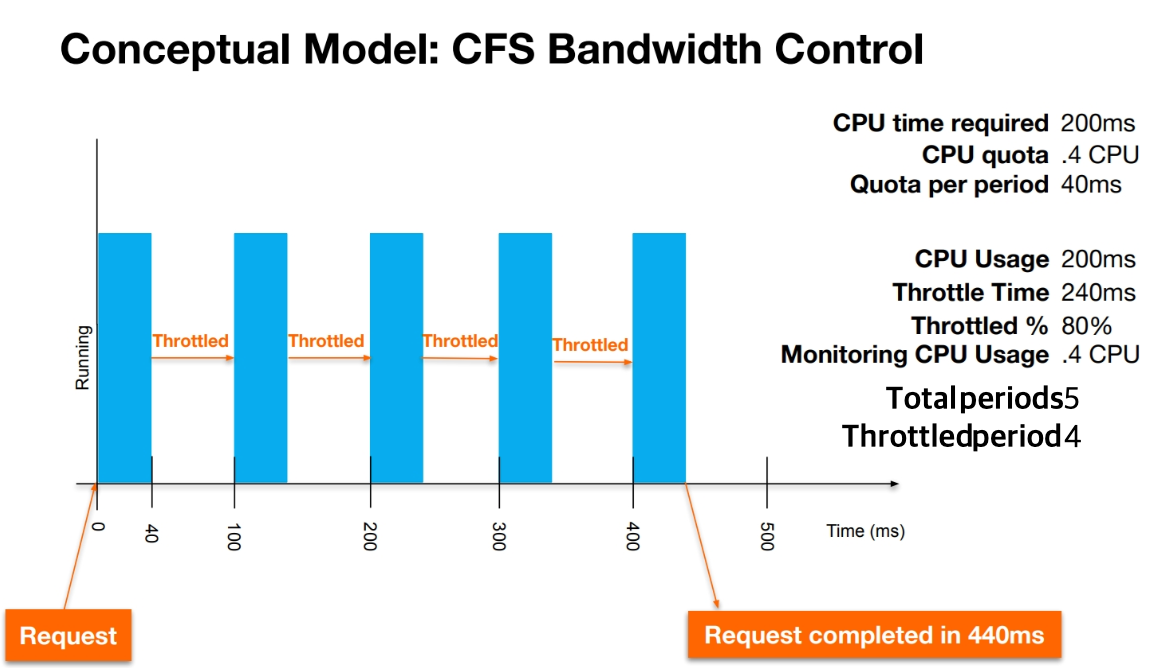
사이사이에 빈 공간이 생기는 것을 볼 수 있는데
바로 여기서 CPU Limit 이 가지는 문제점이 명확하게 드러난다.
리눅스 커널의 CFS 는 100ms 길이의 Time Slice 를 이용해 CPU 시간을 공평하게 할당하는데,
CPU Limit 이 0.4 라면 이 100ms 의 40% 인 40ms 만 사용하도록 제한한다
따라서 CPU Limit 0.4 인 파드가 200ms 의 요청을 처리하기 위해서는
(160ms / 40ms * 100ms) + 40ms = 440 ms 가 된다
즉 200ms 의 처리시간을 위해 240ms 를 기다리며 손가락만 빨아야 하는 상황으로
실제 일하는 시간보다 기다리는 시간이 더 길다!
이렇게 아무것도 하지 않고 기다리는 시간 240ms 를 "CPU Throttling"이라고 부른다.
CPU Throttling 은 특히 순간적인 처리량이 필요한, 다시말해, bursty 한 워크로드에 가장 큰 영향을 끼치는데
웹 트래픽의 대부분이 bursty 한 특성을 가진다는 것을 생각해보면 상당히 큰 의미를 가짐을 알 수 있다.
그래서 쓰지 마?
여느 기술들이 그렇겠지만 반드시 라는건 없다.
아래와 같은 경우에는 충분히 CPU Limit 이 빛을 발할 수 있을것이라고 생각한다
- 검증된 워크로드
이미 충분한 부하 테스트를 통해 정확한 리소스 사용량을 알고있다면 Limit 을 걸지 않을 이유가 없다. - 자원 폭주가 우려되는 상황에서는 Limit 을 설정하자.
파일 압축, 썸네일 변환, 텍스트 인덱싱 처럼 소요시간이 어플리케이션에 크리티컬한 영향을 미치지 않는다면
적정한 수준에서 Limit 을 설정해 자원폭주를 방지하는 것이 좋겠다. - 멀티 테넌트
하나의 쿠버네티스 클러스터를 여러 조직이 공유해서 사용한다면 다른 팀을 위해서라도 Limit 을 적용하자.
더욱이 프로메테우스의 node exporter 에서는 CPU Throttling 을 모니터링 할 수 있는 지표도 제공한다
https://stackoverflow.com/a/67316429
`throttled percentage` := `container_cpu_cfs_throttled_periods_total / container_cpu_cfs_periods_total`
위의 쿼리를 이용해 개개별 컨테이너의 CPU Throttling % 를 쿼리할 수 있다.
만약 CPU Limit 을 적용했다면 해당 지표를 이용해 사용량을 최적화하자.
이번글을 쓰면서 무심코 bitnami helm 차트로 올린 redis-cluster 에서 무려 30%를 상회하는 CPU Throttling 이 발생하고 있다는것을 알게되었다;;
CPU Limit 을 상향조치하여 해소할 수 있었지만 이런식으로 인지하지 못한 채 낭비되는 리소스가 참 많겠구나 싶었다.
앞으로도 지표를 꼼꼼히 모니터링하고, 실제 서비스에 맞는 최적의 설정을 찾아보자.