레디스 클러스터 Deep Dive (1)

회사에서 서비스 운영을 위해 인프라 구성을 하다보면 종종 접하게 되는 레디스.
인프라 장애의 쓴맛을 맛본 나는 본능적으로 레디스 클러스터로 구성하지만
왜, 그리고 어떻게 클러스터가 동작하는지는 잘 모르고 구성한 탓에 문제가 발생하면 대응이 힘들거나 튜닝을 못해 충분한 성능을 발휘하지 못한 경우가 많았다
궁금증도 해결할 겸, 공부도 할 겸 아래의 공식 문서를 바탕으로
레디스가 어떻게 동작하는지 구체적으로 정리해 보았다.
클러스터 토폴로지
기본적으로 클러스터가 아닌 레디스는 마스터(1개)-레플리카(N개) 구조를 지원한다
여타 마스터-레플리카 구조와 같이 마스터 노드는 쓰기/읽기 동작을, 레플리카는 오로지 읽기만 가능하다
따라서 레플리카 수 증가를 통한 스케일링은 가능하나 단일 마스터 노드로 인해 발생하는 장애 대응은 불가능한 한계를 가지고 있다
이에 레디스는 아래와 같이 장애 대응이 가능한 2가지 형태의 클러스터 토폴로지를 제공한다
- 레디스 센티넬 (Redis Sentinel)
- 레디스 클러스터 (Redis Cluster)
우선 레디스 센티넬은 주기적으로 마스터 노드의 상태를 감시하는 보초병(센티넬)을 두고 만약 마스터 노드에 문제가 생긴다면 레플리카 노드를 마스터로 승격하는 구조이다
그림으로 표현하면 아래와 같다
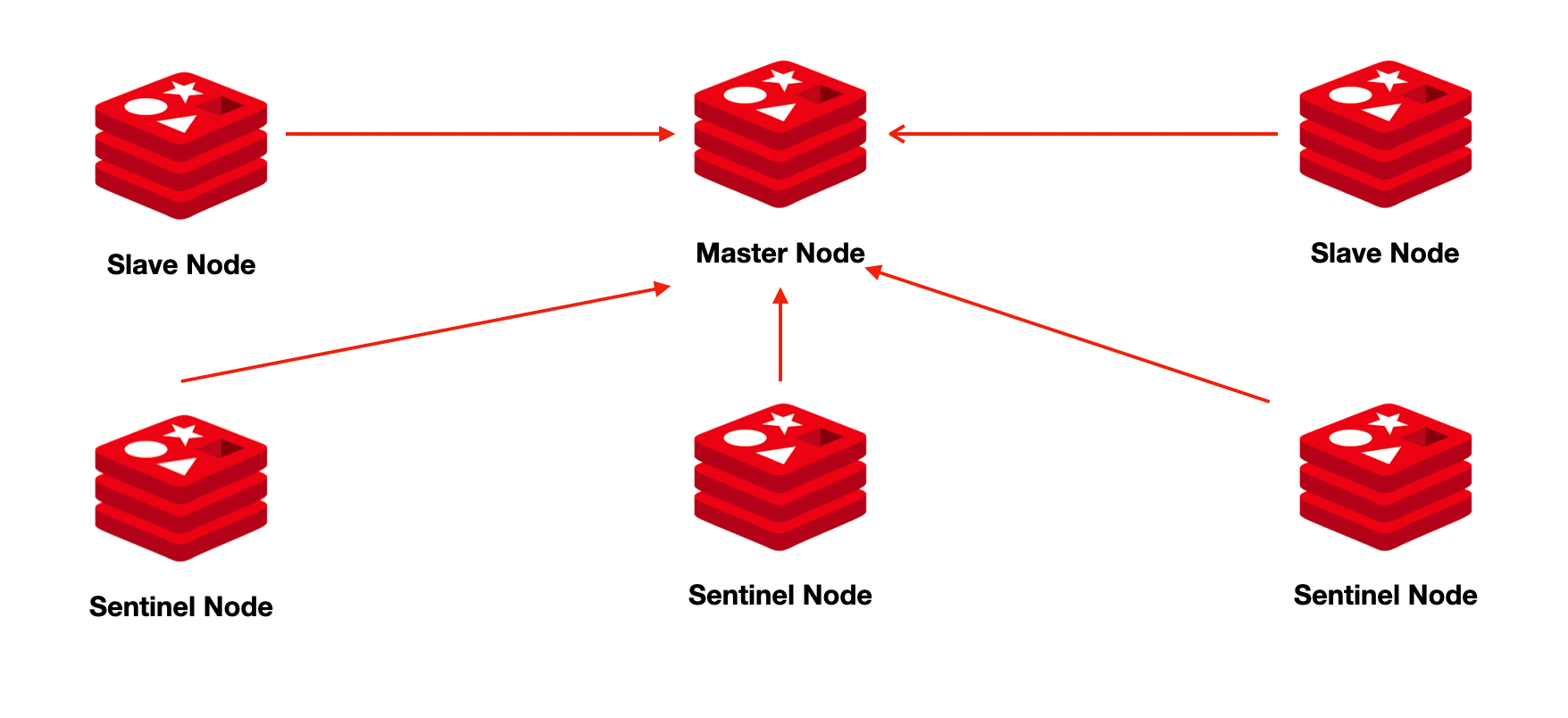
하지만 이 구성은 아래와 같은 문제점이 있다
- 센티넬 또한 SPOF 방지를 위해 단일 노드가 아닌 3개 이상의 Quorum 노드로 구성되어야 한다
- 여전히 단일 마스터 노드로 데이터의 샤딩이 불가능함
이런 한계점으로 높은 Throughput 이 필요한 시스템에는 센티넬 보다는 레디스 클러스터를 이용해 구성하도록 한다
레디스 클러스터는 센티넬과는 다르게 마스터-레플리카 세트 여러개를 묶는 방식을 제시한다
그림으로 표현하면 아래와 같다
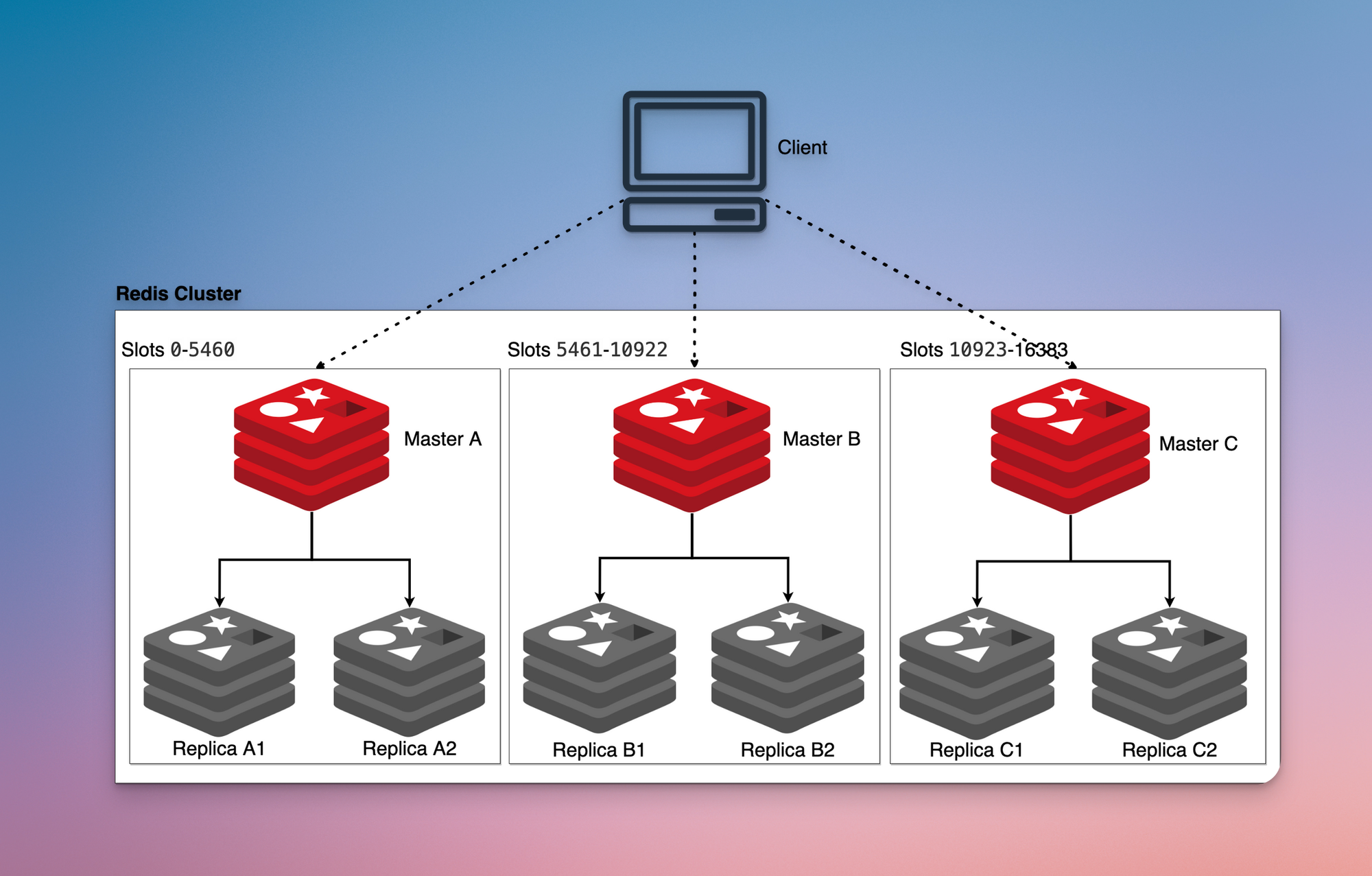
여러개의 마스터 노드가 있으니 데이터가 각각 분산되어 저장되는 구조이다
레디스 공식 메뉴얼에 따르면 레디스 클러스터가 겨냥하는 목표는 아래와 같다
- 데이터셋의 자동 분산
- 클러스터의 가용성
- 어느 정도의 쓰기 일관성
각각의 기능을 어떻게 제공하는지 아래에서 살펴보자
데이터셋의 자동 분산
분산 시스템에서 데이터의 분산은 정답이 없는 문제인데 이러다보니 만드는 사람마다 자신만의 매커니즘을 구현하기 마련이다
아파치의 Kafka 는 파티션을 이용해서 데이터를 분산하고 HDFS 는 데이터를 128MB 단위의 블록으로 쪼개 분산한다
레디스는 어떻게 데이터를 분산할까?
모든 데이터를 분산없이 저장하는 일반 레디스와 다르게 레디스 클러스터 내부의 개개별 마스터-레플리카 세트는 Hash Slot 이라는 고유한 키를 나눠가짐으로써 전체 클러스터에 골고루 데이터를 분산한다
Hash Slot 은 16,384개 라는 정해진 갯수가 있으며 Hash Slot 을 기준으로 데이터가 저장된다
윈도우 컴퓨터를 예로 들자면
16,384개의 폴더(Hash Slot)를 C드라이브, D드라이브 와 같은 디스크들(마스터-레플리카 세트)에 각각 공평하게 나누어서 저장하는 형태라고 볼 수 있겠다
마스터-레플리카 세트 간 데이터의 밸런싱이 필요할 경우 Hash Slot을 이동하는 형태로 진행된다
다시 윈도우 컴퓨터를 예로 들자면
C드라이브에 폴더를 드래그해서 D드라이브로 옮기는 느낌
참고로 레디스 클러스터는 Consistent Hashing 을 사용하지 않는데
재미있게도 16,384개라는 무지막지한 양의 Hash Slot 을 이용해서 잘게잘게 데이터를 쪼개 보관함으로써 Consistent Hashing 의 vnode 와 유사한 기능을 구현했다
어찌보면 Hash Slot 이라는 레디스만의 Consistent Hashing 기법을 구현 한 셈.
따라서 개개별 마스터-레플리카 세트에 Hash Slot 을 분산해서 저장하는 구조의 특성상 이론적으로 클러스터링 가능한 최대 마스터-레플리카 세트는 16,384개로 한정된다
윈도우에 16,384개의 폴더가 있는데 디스크 16,385개에 공평하게 분산해야 한다면?
어느 디스크 하나는 폴더를 한개도 갖지 못하게 되는 것과 같은 현상이다
레디스 스펙시트에는 최대 16,384개의 마스터 노드까지만 클러스터링이 가능하다고 명시되어 있지만 네트워크 지연, 레디스 클러스터 구조의 특성을 감안하면 1,000 개 정도가 현실적인 상한선이라고 한다.
장애에 대한 내구성
레디스 클러스터의 모든 노드들은 클러스터 버스를 통해 일명 PING / PONG 패킷 이라는걸 이용해서 주기적으로 생존여부를 확인한다
이 PING / PONG 패킷을 레디스에서는 하트비트 패킷 이라고 일컫는다
우리가 Ping 이라고 하면 생각하는 그 기능이 맞고 하나의 레디스 노드에서 PING 을 보내면 받는 노드에서 PONG 이라고 응답을 보내준다
일반적으로 하트비트 패킷의 헤더에는 아래와 같은 데이터가 포함된다
- 송신자의 노드ID
- 송신자가 가진 Hash Slot 의 비트맵
- 송신자의 입장에서 바라본 클러스터의 상태 (OK 또는 DOWN)
- 송신자가 레플리카인 경우 마스터 노드의 ID
- Gossip Message
이 외에도 포트나 Epoch 정보들도 있지만 한가지 눈에 띄는 데이터가 있다
Gossip Message? 이게 뭘까?
Gossip Protocol
고십? 가십?

가십 프로토콜 이라고 읽으면 된단다
흔히 "가십거리" 라고 말하는 것과 동일한 단어.
다른 말로 Epidemic Protocol 이라고도 하는데 번역하면 전염병 프로토콜.. 정도가 되겠다
이름처럼 전염병이 퍼지는 현상을 보고 만든 프로토콜이라고.
가십 프로토콜은 레디스 클러스터에서 노드들이 정보를 공유하는데 사용하는 핵심 기능인데 그 작동방식이 재미있다
Gossip Message 을 살펴보면 아래의 항목들이 포함되어 있는데
- Node ID
- IP & Port
- 노드 플래그
이상한 부분이 있다.
분명 Node ID, 노드 플래그와 같은 정보는 이미 하트비트 패킷에 모두 포함되어 있는데 왜 또 Gossip Message 에 실어서 보내는걸까?
사실 Gossip Message 의 노드이름, 노드IP, 노드상태 등의 데이터는 하트비트 패킷을 보내는 노드가 아닌, 다른 노드의 정보를 담고있다
바로 이 부분이 Gossip Protocol 의 특징 되겠다
즉 하트비트 패킷을 보내는 노드의 관점에서 바라본 다른 노드들의 상태를 공유한다는 뜻이다
대화로 비유해보면 아래와 같다
마스터A : 나 마스터A 인데 마스터C 너 괜찮아?
마스터C : ......
마스터A : 나 마스터A 인데 마스터B 너 괜찮아? 근데 아무래도 마스터C 가 이상한거 같아.
마스터B : 나 괜찮아. 그리고 내가 보기에도 마스터C 가 이상해보여.
마스터A 가 마스터B 로 PING 을 보내면서 Gossip Message 를 통해 다른 마스터 노드의 상태에 관한 '소문'도 퍼뜨린다
참고로 각 노드는 매 초마다 다수의 랜덤 노드에게 Gossip Message 가 포함된 PING 을 전송하는데
여기서 랜덤 노드의 수는 전체 노드의 10% 또는 3개 중 큰 수로 결정된다
그럼 이제 응답이 없는 마스터C 에게는 무슨일이 일어나는걸까?
클러스터의 노드 장애 감지
레디스 클러스터는 마스터 노드의 장애 상태를 2가지로 나눈다
- PFAIL (Possible Failure)
노드의 상태는 확인되지 않으나 일단 지켜보는 상태 - FAIL
최종 장애가 발생한 것으로 인지된 상태
이해를 돕기위해 위의 Gossip Message 대화 예제를 확장해보자
마스터A : 나 마스터A 인데 마스터C 너 괜찮아?
마스터C : ......
마스터A : 나 마스터A 인데 마스터B 너 괜찮아? 근데 아무래도 마스터C 가 이상한거 같아.
마스터B : 나 괜찮아. 그리고 내가 보기에도 마스터C 가 이상해보여.
- 마스터A 가 마스터C 에게 PING을 보내고 일정 시간동안 마스터C의 응답을 기다렸으나 받지 못한다. 이 때 마스터A는 마스터C 를 PFAIL 상태로 마킹한다
- 마스터A 가 마스터B 에게 PING 을 전송하며 마스터C 가 이상하다고 말한다
- 마스터B 가 마스터A 에게 응답을 주며 마스터C 가 이상하다는 것에 동의한다
- 마스터A 는 과반수의 동의를 얻었다고 판단하며 최종적으로 마스터C 를 FAIL 처리하고 클러스터의 마스터와 레플리카를 포함한 모든 노드에 소식을 전파한다
위와 같은 방식으로 레디스 클러스터는 어떤 노드에 장애가 발생했는지 상호 합의 에 도달하게 된다
더불어 볼드 처리한 일정 시간에 집중하자
일정 시간을 레디스 설정에서는 NODE_TIMEOUT 이라고 정의한다
레디스 공식 문서 기준 15초의 기본값을 가지는 이 값은 매우 중요한데
클러스터가 얼마나 민첩하게 장애를 감지하는지 정의하는 밀리초 단위의 설정이다.
포럼에 따르면 3 ~ 5초를 권장한다
http://redisgate.kr/redis/cluster/cluster-node-timeout.php
하지만 노드가 PING 명령어 자체를 실행하는데 1초 이상이 걸리는 경우도 있으니 너무 과다하게 줄이지는 말자.
레플리카의 승격
이제 클러스터는 마스터C 에 문제가 있다는것을 알게되었다.
그럼 어떻게 대응할까?
마스터C 의 장애 상황을 전파받은 레플리카 노드들은 아래의 조건이 만족되었을 때 자신을 마스터 노드로 승격을 요청한다
- 자신의 마스터 노드가 FAIL 상태일 것
- 자신의 마스터 노드가 1개 이상의 Hash Slot 을 가지고 있을 것
- 마스터 노드와 연결이 끊어진 후 어느정도 시간 내에 있는 레플리카 노드일 것
조건에 해당하는 레플리카 노드는 모든 마스터 노드에게 FAILOVER_AUTH_REQUEST 패킷을 보내 승격 투표를 요청한다
마스터 노드에게서 과반수 이상의 찬성표를 받은 레플리카 노드에게는 FAILOVER_AUTH_ACK 패킷이 전송되며 최종 마스터 노드로 선출된다
선출 이후에는 장애 감지와 마찬가지로 하트비트 패킷과 Gossip Message 를 통해 자신이 마스터가 되었음을 클러스터에 전파한다
이번 글을 통해 레디스 클러스터의 기본적인 동작에 대해서 알아보았다
하지만 아직 해결되지 않은 궁금증도 많다
- 마스터-레플리카 세트 간의 부하분산은 어떻게 처리되는걸까?
- 클라이언트는 어떤 마스터-레플리카 세트에 접속해야 할까?
- 레플리카 노드의 승격시에 어떤 레플리카 노드가 적합한지는 어떻게 판단하는 걸까?
- 멀티 마스터에서 발생하는 Split-Brain 현상은 어떻게 대처하는걸까?
이런 질문들은 다음 글을 통해 알아보도록 하자